
Training a Diffusion Model on CIFAR-10
Referenced code by Katherine Crowson (Github)
Imports and Utility Functions
from contextlib import contextmanager
from copy import deepcopy
import math
from IPython import display
from matplotlib import pyplot as plt
import torch
from torch import optim, nn
from torch.nn import functional as F
from torch.utils import data
from torchvision import datasets, transforms, utils
from torchvision.transforms import functional as TF
from tqdm.notebook import tqdm, trange
Below we define a few utility functions.
train_mode is a context manager that sets the model to training mode and restores the previous mode on exit.
eval_mode is a context manager that sets the model to evaluation mode and restores the previous mode on exit.
ema_update is a function that updates the exponential moving average of the model parameters. It should be called after each optimizer step.
@contextmanager
def train_mode(model, mode=True):
modes = [module.training for module in model.modules()]
try:
yield model.train(mode)
finally:
for i, module in enumerate(model.modules()):
module.training = modes[i]
def eval_mode(model):
return train_mode(model, False)
@torch.no_grad()
def ema_update(model, averaged_model, decay):
model_params = dict(model.named_parameters())
averaged_params = dict(averaged_model.named_parameters())
assert model_params.keys() == averaged_params.keys()
for name, param in model_params.items():
averaged_params[name].mul_(decay).add_(param, alpha=1 - decay)
model_buffers = dict(model.named_buffers())
averaged_buffers = dict(averaged_model.named_buffers())
assert model_buffers.keys() == averaged_buffers.keys()
for name, buf in model_buffers.items():
averaged_buffers[name].copy_(buf)Model Architecture: Residual U-Net
We will define the model architecture as a residual u-net.
ResidualBlock composes of a main network and a skip network, where the skip is the identity unless specified.
ResConvBlock is a convolutional block with two convolutional layers and a skip connection.
SkipBlock is a block that concatenates the output of the main network and the skip network.
FourierFeatures is a layer that computes the Fourier features of the input.
expand_to_planes is a function that expands the input to the same shape as the output of the model.
Diffusion is the main model class that defines the architecture of the diffusion model. timestep_embed are the Fourier features of the timestep, and class_embed is the class embedding.
The network taks the input image (3 channels, RGB), the timestep embedding (16 channels), and the class (4 channels) as input, resulting in an input tensor of shape (3+16+4)*32*32 (spatial dimensions).
The convolutional layers of ResConvBlock make the channel count (3+16+4) -> c -> c -> c -> c.
AvgPool2d(2) reduces the spatial dimensions by a factor of 2, and Upsample(scale_factor=2) increases the spatial dimensions by a factor of 2.
The final output of the model is a tensor of shape 3*32*32, which is the same shape as the input image.
class ResidualBlock(nn.Module):
def __init__(self, main, skip=None):
super().__init__()
self.main = nn.Sequential(*main)
self.skip = skip if skip else nn.Identity()
def forward(self, input):
return self.main(input) + self.skip(input)
class ResConvBlock(ResidualBlock):
def __init__(self, c_in, c_mid, c_out, dropout_last=True):
skip = None if c_in == c_out else nn.Conv2d(c_in, c_out, 1, bias=False)
super().__init__([
nn.Conv2d(c_in, c_mid, 3, padding=1),
nn.Dropout2d(0.1, inplace=True),
nn.ReLU(inplace=True),
nn.Conv2d(c_mid, c_out, 3, padding=1),
nn.Dropout2d(0.1, inplace=True) if dropout_last else nn.Identity(),
nn.ReLU(inplace=True),
], skip)
class SkipBlock(nn.Module):
def __init__(self, main, skip=None):
super().__init__()
self.main = nn.Sequential(*main)
self.skip = skip if skip else nn.Identity()
def forward(self, input):
return torch.cat([self.main(input), self.skip(input)], dim=1)
class FourierFeatures(nn.Module):
def __init__(self, in_features, out_features, std=1.):
super().__init__()
assert out_features % 2 == 0
self.weight = nn.Parameter(torch.randn([out_features // 2, in_features]) * std)
def forward(self, input):
f = 2 * math.pi * input @ self.weight.T
return torch.cat([f.cos(), f.sin()], dim=-1)
def expand_to_planes(input, shape):
return input[..., None, None].repeat([1, 1, shape[2], shape[3]])
class Diffusion(nn.Module):
def __init__(self):
super().__init__()
c = 64 # The base channel count
# The inputs to timestep_embed will approximately fall into the range
# -10 to 10, so use std 0.2 for the Fourier Features.
self.timestep_embed = FourierFeatures(1, 16, std=0.2)
self.class_embed = nn.Embedding(10, 4)
self.net = nn.Sequential( # 32x32
ResConvBlock(3 + 16 + 4, c, c),
ResConvBlock(c, c, c),
SkipBlock([
nn.AvgPool2d(2), # 32x32 -> 16x16
ResConvBlock(c, c * 2, c * 2),
ResConvBlock(c * 2, c * 2, c * 2),
SkipBlock([
nn.AvgPool2d(2), # 16x16 -> 8x8
ResConvBlock(c * 2, c * 4, c * 4),
ResConvBlock(c * 4, c * 4, c * 4),
SkipBlock([
nn.AvgPool2d(2), # 8x8 -> 4x4
ResConvBlock(c * 4, c * 8, c * 8),
ResConvBlock(c * 8, c * 8, c * 8),
ResConvBlock(c * 8, c * 8, c * 8),
ResConvBlock(c * 8, c * 8, c * 4),
nn.Upsample(scale_factor=2),
]), # 4x4 -> 8x8
ResConvBlock(c * 8, c * 4, c * 4),
ResConvBlock(c * 4, c * 4, c * 2),
nn.Upsample(scale_factor=2),
]), # 8x8 -> 16x16
ResConvBlock(c * 4, c * 2, c * 2),
ResConvBlock(c * 2, c * 2, c),
nn.Upsample(scale_factor=2),
]), # 16x16 -> 32x32
ResConvBlock(c * 2, c, c),
ResConvBlock(c, c, 3, dropout_last=False),
)
def forward(self, input, log_snrs, cond):
timestep_embed = expand_to_planes(self.timestep_embed(log_snrs[:, None]), input.shape)
class_embed = expand_to_planes(self.class_embed(cond), input.shape)
return self.net(torch.cat([input, class_embed, timestep_embed], dim=1))The Noise Schedule
The noise schedule is defined by alphas and sigmas, which are the scaling factors for the clean image and the noise, respectively.
get_alphas_sigmas takes the log SNR for a timestep as input and returns the scaling factors for the clean image (alpha) and for the noise (sigma).
get_ddpm_schedule returns the log SNRs for the noise schedule from the DDPM paper.
def get_alphas_sigmas(log_snrs):
return log_snrs.sigmoid().sqrt(), log_snrs.neg().sigmoid().sqrt()
def get_ddpm_schedule(t):
return -torch.special.expm1(1e-4 + 10 * t**2).log()We may also visualize the noise schedule.
plt.rcParams['figure.dpi'] = 100
t_vis = torch.linspace(0, 1, 1000)
log_snrs_vis = get_ddpm_schedule(t_vis)
alphas_vis, sigmas_vis = get_alphas_sigmas(log_snrs_vis)
print('The noise schedule:')
plt.plot(t_vis, alphas_vis, label='alpha (signal level)')
plt.plot(t_vis, sigmas_vis, label='sigma (noise level)')
plt.legend()
plt.xlabel('timestep')
plt.grid()
plt.show()
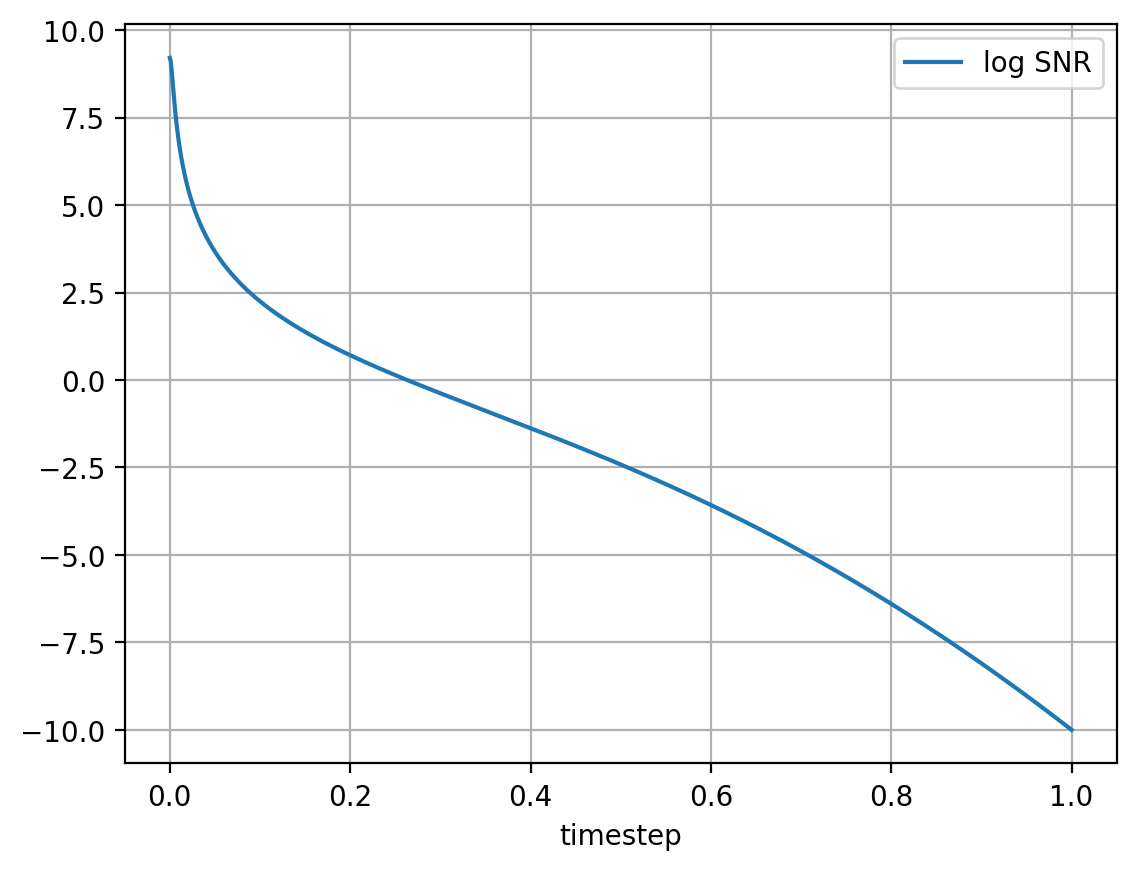
plt.plot(t_vis, log_snrs_vis, label='log SNR')
plt.legend()
plt.xlabel('timestep')
plt.grid()
plt.show()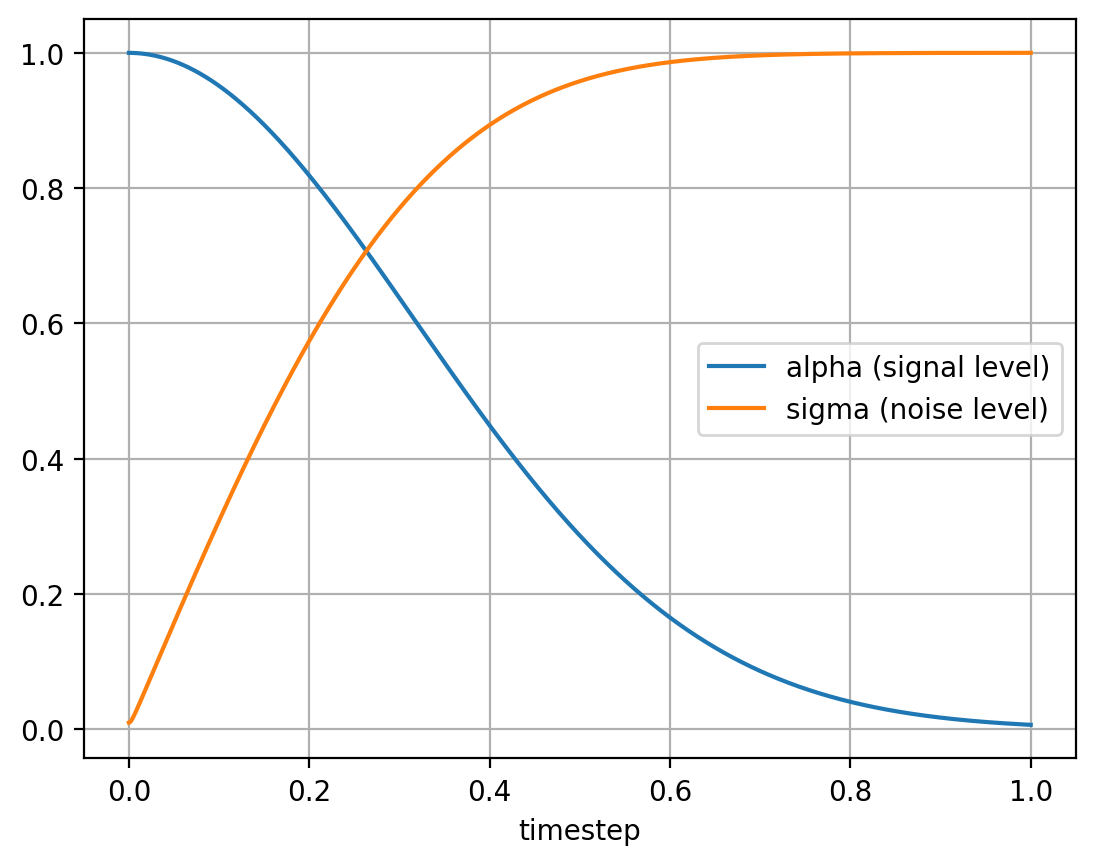
Preparing the Dataset (CIFAR-10)
We load the CIFAR-10 dataset (170MB) with a batch size of 100.
batch_size = 100
tf = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
])
train_set = datasets.CIFAR10('data', train=True, download=True, transform=tf)
train_dl = data.DataLoader(train_set, batch_size, shuffle=True,
num_workers=4, persistent_workers=True, pin_memory=True)
val_set = datasets.CIFAR10('data', train=False, download=True, transform=tf)
val_dl = data.DataLoader(val_set, batch_size,
num_workers=4, persistent_workers=True, pin_memory=True)Create the Model and Optimizer
We use the Adam optimizer with learning rate 2e-4. rng is a low discrepancy quasi-random sequence to sample uniformly distributed timesteps. This considerably reduces the between-batch variance of the loss.
seed = 0
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
torch.manual_seed(0)
model = Diffusion().to(device)
model_ema = deepcopy(model)
print('Model parameters:', sum(p.numel() for p in model.parameters()))
opt = optim.Adam(model.parameters(), lr=2e-4)
scaler = torch.cuda.amp.GradScaler()
epoch = 0
rng = torch.quasirandom.SobolEngine(1, scramble=True)Sampling an Image from a Model given the Initial Noise
When sampling, we use @torch.no_grad() to disable gradient tracking, which is not needed during inference.
sample takes the model, the initial noise, the number of steps, the amount of additional noise to add (eta), and the class as input.
In this implementation, we use the velocity prediction, v, which is used to predict the noise eps and the denoised image pred.
Until the last step, the sampling loop computes the noisy image for the next timestep.
If eta > 0, adjust the scaling factor for the predicted noise downward according to the amount of additional noise to add.
Then, recombine the predicted noise and predicted denoised image in the correct proportions for the next step.
Note that eta = 0 is equivalent to the DDIM sampling algorithm where the initial noise is the only source of randomness.
Finally, if we are on the last timestep, we return the denoised image.
@torch.no_grad()
def sample(model, x, steps, eta, classes):
ts = x.new_ones([x.shape[0]])
# Create the noise schedule
t = torch.linspace(1, 0, steps + 1)[:-1]
log_snrs = get_ddpm_schedule(t)
alphas, sigmas = get_alphas_sigmas(log_snrs)
# The sampling loop
for i in trange(steps):
# Get the model output (v, the predicted velocity)
with torch.cuda.amp.autocast():
v = model(x, ts * log_snrs[i], classes).float()
# Predict the noise and the denoised image
pred = x * alphas[i] - v * sigmas[i]
eps = x * sigmas[i] + v * alphas[i]
if i < steps - 1:
ddim_sigma = eta * (sigmas[i + 1]**2 / sigmas[i]**2).sqrt() * (1 - alphas[i]**2 / alphas[i + 1]**2).sqrt()
adjusted_sigma = (sigmas[i + 1]**2 - ddim_sigma**2).sqrt()
x = pred * alphas[i + 1] + eps * adjusted_sigma
# Add the correct amount of fresh noise
if eta:
x += torch.randn_like(x) * ddim_sigma
# If we are on the last timestep, output the denoised image
return predTraining the Model
We train the model with ema_decay = 0.998 and sample with 500 steps. The code below implements DDPM sampling where eta = 1.
eval_loss computes the loss for a batch of images and the corresponding classes.
train trains the model for one epoch, and val validates the model on the validation set.
demo samples an image from the model and saves it to a file.
save saves the model parameters, optimizer state, and epoch number to a file.
ema_decay = 0.998
# The number of timesteps to use when sampling
steps = 500
# The amount of noise to add each timestep when sampling
# 0 = no noise (DDIM) / 1 = full noise (DDPM)
eta = 1.
def eval_loss(model, rng, reals, classes):
# Draw uniformly distributed continuous timesteps
t = rng.draw(reals.shape[0])[:, 0].to(device)
# Calculate the noise schedule parameters for those timesteps
log_snrs = get_ddpm_schedule(t)
alphas, sigmas = get_alphas_sigmas(log_snrs)
weights = log_snrs.exp() / log_snrs.exp().add(1)
# Combine the ground truth images and the noise
alphas = alphas[:, None, None, None]
sigmas = sigmas[:, None, None, None]
noise = torch.randn_like(reals)
noised_reals = reals * alphas + noise * sigmas
targets = noise * alphas - reals * sigmas
# Compute the model output and the loss.
with torch.cuda.amp.autocast():
v = model(noised_reals, log_snrs, classes)
return (v - targets).pow(2).mean([1, 2, 3]).mul(weights).mean()
def train():
for i, (reals, classes) in enumerate(tqdm(train_dl)):
opt.zero_grad()
reals = reals.to(device)
classes = classes.to(device)
# Evaluate the loss
loss = eval_loss(model, rng, reals, classes)
# Do the optimizer step and EMA update
scaler.scale(loss).backward()
scaler.step(opt)
ema_update(model, model_ema, 0.95 if epoch < 20 else ema_decay)
scaler.update()
if i % 50 == 0:
tqdm.write(f'Epoch: {epoch}, iteration: {i}, loss: {loss.item():g}')
@torch.no_grad()
@torch.random.fork_rng()
@eval_mode(model_ema)
def val():
tqdm.write('\nValidating...')
torch.manual_seed(seed)
rng = torch.quasirandom.SobolEngine(1, scramble=True)
total_loss = 0
count = 0
for i, (reals, classes) in enumerate(tqdm(val_dl)):
reals = reals.to(device)
classes = classes.to(device)
loss = eval_loss(model_ema, rng, reals, classes)
total_loss += loss.item() * len(reals)
count += len(reals)
loss = total_loss / count
tqdm.write(f'Validation: Epoch: {epoch}, loss: {loss:g}')
@torch.no_grad()
@torch.random.fork_rng()
@eval_mode(model_ema)
def demo():
from IPython.display import clear_output
clear_output(wait=True)
tqdm.write('\nSampling...')
torch.manual_seed(seed)
noise = torch.randn([100, 3, 32, 32], device=device)
fakes_classes = torch.arange(10, device=device).repeat_interleave(10, 0)
fakes = sample(model_ema, noise, steps, eta, fakes_classes)
grid = utils.make_grid(fakes, 10).cpu()
filename = f'demo_{epoch:05}.png'
TF.to_pil_image(grid.add(1).div(2).clamp(0, 1)).save(filename)
display.display(display.Image(filename))
tqdm.write('')
def save():
filename = 'cifar_diffusion.pth'
obj = {
'model': model.state_dict(),
'model_ema': model_ema.state_dict(),
'opt': opt.state_dict(),
'scaler': scaler.state_dict(),
'epoch': epoch,
}
torch.save(obj, filename)Run the Training Loop
try:
val()
demo()
while epoch < 10:
print('Epoch', epoch)
train()
epoch += 1
val()
demo()
save()
except KeyboardInterrupt:
pass
